egox: egocentric video generation from exocentric footage
egox introduces a novel framework for synthesizing egocentric (first-person) videos from a single exocentric (third-person) input video. this task presents significant challenges due to extreme viewpoint differences and occlusions, requiring the model to hallucinate unseen regions while maintaining geometric consistency.
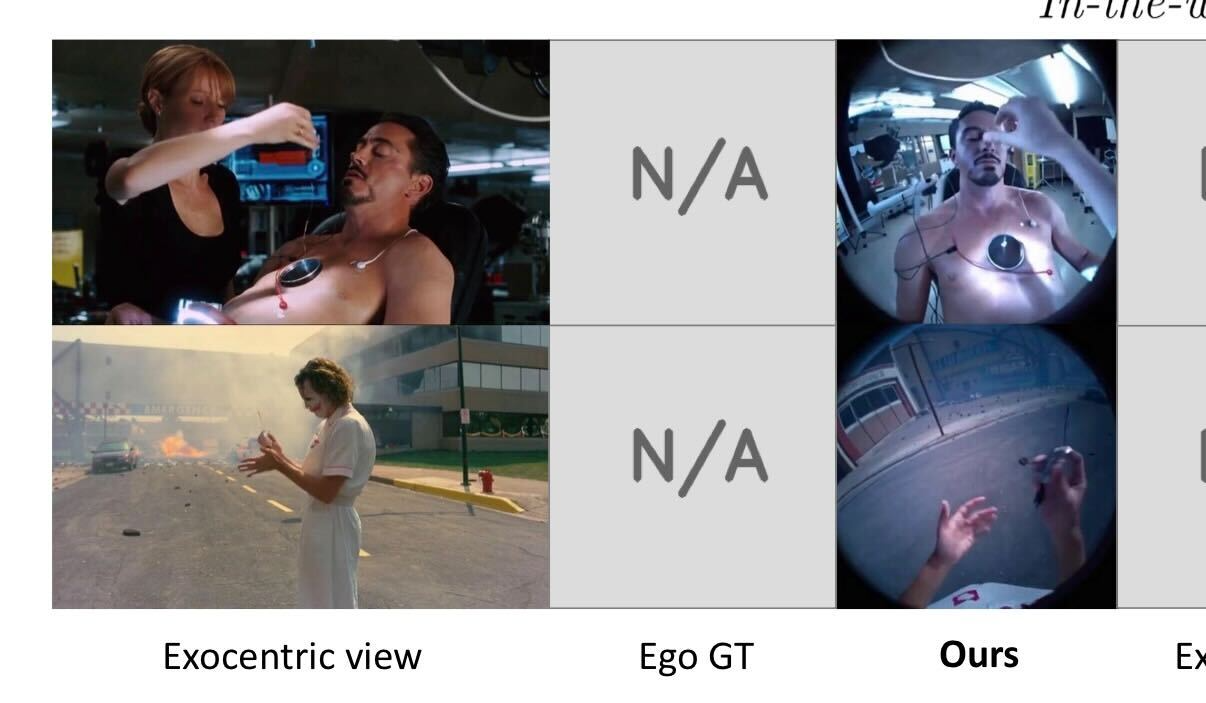
methodology
the approach leverages the strong priors of large-scale pre-trained video diffusion models. the pipeline consists of three key components:
- 3d reconstruction: a point cloud is reconstructed from the input video to provide explicit geometric guidance.
- unified conditioning: the egocentric geometric prior is concatenated width-wise with the exocentric frames, allowing the model to attend to both the target geometry and the source appearance.
- lora fine-tuning: a lightweight low-rank adaptation (lora) is applied to the diffusion model, enabling it to learn the mapping from exocentric to egocentric domains without extensive retraining.
implications
this work highlights the growing capability of foundation models to be adapted for specific, geometrically complex tasks through efficient fine-tuning strategies. rather than training from scratch, we can now effectively steer pre-trained video models to perform novel view synthesis tasks by injecting appropriate geometric priors.